
Having actively used RavenDB for a couple of years (from v3.5 to v4.2), I constantly get asked by other devs about feedback on the database. They usually expect to hear something simple and straightforward, like ”love it” or maybe even ”hate it”, but my experience doesn’t fall into any of these extremes. After 2 years I’m torn apart by polarised feelings about the database, and my expected-to-be-simple response turns into a long story about all the pros and cons, love and hatred. So, here is my story.
For ones who don’t know much about RavenDB, I’ll save you a click — it’s a NoSQL database written in .NET Core and initially was targeting the .NET infrastructure, but now also supports Java, Python and NodeJS. It was founded by Oren Eini (aka Ayende Rahien), who contributed a lot to NHibernate ORM and undoubtedly has some weight in the .NET community.
It’s been 9 years since v1.0 of Raven was released and one would expect to see a very mature NoSQL database. To put it into perspective, in a 9-year time from v1 Microsoft released SQL Server 7, which sure had some rough edges, but represented quite a sturdy and functional DB.
So how mature is RavenDB and what’s the pleasure and pain of dealing with it for a mere mortal .NET developer?
The bright side
Decent .NET Integration
RavenDB is designed to describe persistence models and indexes in the .NET code (the Code First approach). I was pleased to discover that the produced code is even lighter than in the Entity Framework.
RavenDB provides a very convenient Client API, which implements the Unit of Work pattern, has extensions to map models, etc. It does make dev’s life a bit easier by providing NuGet packages for unit testing and DB migration.
Comparing to other NoSQL databases (though, I have modest experience), it seems that Raven’s .NET client API trumps MongoDB .NET Driver, CosmosDB + Cosmonaut bundle and leaves smaller players like Cassandra (with DataStax C# Driver), CouchDB (with MyCouch) completely out of the competition.
Good pace of development
The product is rapidly evolving. New versions get released regularly with fixed bugs and tempting new features. Check out the what’s new or Oren Eini’s blog with a deep dive in all the new stuff.
Helpful technical support
It’s not easily discoverable, but RavenDB has a great technical support on Google Groups for no costs. All questions, regardless of the obtained license, get meaningful answers within 24 hours and quite often Oren Eini responds personally.
Contrary to the Google Groups, questions on StackOverflow are often neglected. It’s a mystery why Raven sticks to a such archaic style of tech support and hasn’t migrated to StackOverflow or GitHub. Especially, when they recently had a good opportunity after releasing a new engine in v4.0 when most of old topics became irrelevant.
Cloud hosting
Starting this month, RavenDB is available on AWS and Azure clouds. It’s coming with way more transparent rates, comparing to insanely tangled rates of CosmosDB. Even better, there is a free option on AWS for the lowest configuration.

Documentation & community (not the bright side)
RavenDB does have the official docs, which are easily navigable and searchable. Works well for beginners and provides good samples to start with, but there are gaps here and there, and it has far less coverage of the functionality than many popular free and open source projects. I don’t compare with the docs of Angular or other popular JavaScript frameworks. Overall, it’s comparable to the docs of PostgreSQL, but the later has a way stronger community, so why would one even read the docs when StackOverflow always has an answer… :)
Ultimately, as a developer, I want to google my question and it’s acceptable to have the answer on a non-official website. But if you’re having a deep dive with RavenDB, it’s unlikely to find it in the official docs, nor StackOverflow, nor GitHub. Probably, their Google Groups have the answer, but untangling their threads is an incredibly tedious and labour-intensive process.
It’s getting darker from here.
The dark side
RavenDB is lacking many things, e.g. there is no profiler to see the actual request sent to the server (people complain). But absence of a tool is not a crime, when bugs can be :).
Stability issues
It’s reliable and does work well. Unless it doesn’t. And then a fix gets promptly released (a nightly build could be available within 24 hours after reporting the issue). And it works well again.
Here are some of the issues I have encountered:
- Failure in modifying indexes leaves them in an unclear state (bug-report).
- Upgrade from v4.1.3 to v4.1.4 causes RavenDB crash on start (bug-report).
- RavenDB v4 service stops working after Windows Update KB4487017 (bug-report).
- Unpredictable behaviour when a DB is deleted and created again with the same name (bug-report).
All these bugs (and others I found) have been promptly fixed. None of them affected the production in my case. Running containers prevents most of the bugs from getting into the production.
Sure, any software can have bugs, maybe nothing to worry about? Hmm… we can bear development hurdles, but stability of the server and the database integrity are sacred. Even a slight risk of losing it can keep you awake at night. So no, it’s a biggy, unless the RavenDB team convinces me otherwise.
Sketchy LINQ support
RavenDB supports 3 ways to query a database:
- a SQL-like language called RQL (RavenDB Query Language);
- a low-level API on the top of RQL named DocumentQuery;
- a high-level Query method with
LINQsupport.
Usually, there are no issues with using RQL, as it’s the “bare metal”, but it requires constructing query strings manually. DocumentQuery is a step up, but no LINQ support. It all leaves us with the Query option, where we can leverage the power of LINQ and Expression Trees. And here you need to be prepared for gotchas. But some theory first.
RavenDB v4.0 can run JavaScript on the server and JavaScript functions can be used in the queries and even indexes. Awesome! Honestly. Now guess how a LINQ or any expression tree gets executed on the server, which is written in .NET Core?
Check out the diagram below.
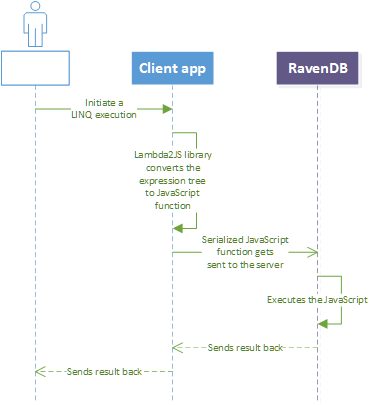
On execution, the expression tree gets converted to a JavaScript function by an open source library Lambda2Js, then the body of the function gets passed to the server, which executes the JavaScript in Jint (open source JavaScript Interpreter for .NET). How many points of failure do you see here?.. Of course, the main one is Lambda2Js. Dealing with expression trees is a very non-trivial task, but successfully converting them to another language is close to black magic.
Not counting “minor” gotchas (e.g. this example on selecting a dictionary property), let me give you a sense of how often you’ll see LINQ queries throwing NotSupportedException in runtime:
-
Have a collection property? Try to query items where an element is not present in the collection or the collection is empty, like
from dog in session.Query<Dog>() where !dog.Awards.Any() select dogThe negating doesn’t work. It’s funny how to fix it
from fog in session.Query<Dog>() where dog.Awards.Any() == false select dogThe issue was reported in 2012 and has status ”won’t fix“.
-
Any date/time manipulation in the query. Have a date field? Try to call any
DateTimemethod inselectorwhereof your query. Likefrom p in session.Query<Client>() select p.EventTime.AddHours(1)It will fail. The only workaround is executing hand-crafted JavaScript string in a query, like
from p in session.Query<Client>() select RavenQuery.Raw<DateTime>("new Date((new Date(p.EventTime)).setHours((new Date(p.EventTime)).getHours() + 1))")and there is a reason for repeating
new Date()3 times. -
Using any extension methods from
Systemnamespace. It’s out of the picture ”by design“.
About the last two. Perhaps, people coming from other ORMs and databases would say that I’m insane, as “special” methods never work against IQueryable. But in front of us a special case — a database written in the .NET! There is no need in converting a query to SQL or JavaScript. Alternatively, the RavenDB team could contribute to Lambda2Js and provide implementation of the most common .NET methods in JavaScript or at least high-level wrappers like SqlFunctions in .NET.
So, no, I’m not a spoiled kid and insufficient LINQ implementation counts as a downside.
In case someone from the Reven’s team is reading this, please consider a second option for running queries sent from .NET clients by leveraging Serialize.Linq library for serializing LINQ expressions and executing the deserialized expression on the server (just queries, no indexes at first). Yes, I’m asking for a special treatment of the .NET devs, but this feature would really stand you out.
Having said all of that, I should underscore that I understand the Raven’s direction to be open to as many platforms/languages as possible. And nowadays, JavaScript is the most popular language, which can be understood by any dev.
“Features” in the query language
Let’s forget LINQ for a minute. Even the RQL (RavenDB Query Language) has some counterintuitive behaviour.
-
Want to check that a property doesn’t exist? This RQL query won’t work (reported here):
from Records where not exists(Amount)and here is a fix:
from Records where true and not exists(Amount) -
undefinedvalue defers fromnull. Yes, it’s coming from the JavaScript engine under the hood. And you have to remember about that JavaScript behaviour when craftingRQLorLINQ. Here is an example on how you can get caught:-
Query against an index returns records, where
from index 'Entities/ForList' where Number != nullNumberhas a value andNumberisundefined -
Query against a collection returns records, where
from 'Entities' where Number != nullNumberhas a value -
Both queries return 1 record, there Number is
from index 'Entities/ForList' where Number == null from 'Entities' where Number == nullnull.
OK. I get it that
undefinedandnullare different, but why a request against an indexed value gives a different result from the same request against the collection? For me it’s a bug. -
Other unhappy stories
There is a couple of unhappy experiences of using RavenDB from some respectful guys:
- Paul Stovell switched Octopus from RavenDB to SQL Server in 2014 due to a need in rebuilding indexes, the “safe by default” philosophy, and index/data corruption.
- Jeremy Miller described his negative experience in 2013. Later he started a very interesting project called Marten — .NET interface to work with JSON fields of PostgreSQL database. In 2016 he posted Moving from RavenDb to Marten.
These stories are dated, so how much of them is still relevant?
Clearly, back in the early days RavenDB was going through the teething stage. I’ll show an example of Raven’s evolution on the ”safe by default” philosophy referenced in the Paul Stovell’s story. The ”Safe by default” is an umbrella term covering a bunch of features, which had nothing to do with safety, but rather reinforcement of high performance by preventing any behaviour, which slows the server down. Bright idea, but its implementation often lets developers down.
Those features were including limiting the number of returned query results (1,024 by default). Oren Eini used to take a firm stand on it, pointing out that a streaming method should be used for requesting a larger number of records. But this constraint caused different bugs in production, which were not caught in testing (due to using a smaller number of records there). And if a sloppy code has slid into the production, the dev community would prefer a slowed performance and a warning in the server logs rather than thrown exceptions. The anticipated change came in v4.0 and this problem can be crossed over now.
Though, another “safety” feature is still remaining — limiting number of requests per session (30 by default) and throwing a runtime exception if exceeded (though, the limit can be changed). I’m absolutely agree that if as much as 30 requests are made during one session, it’s likely a sign of misusing the RavenDB session. And the dev environment throwing a runtime exception is acceptable and even preferable to attract dev’s attention. However, as in the previous example, I’d preferred a slowed performance in production and a warning in the server logs rather than a runtime exception.
A hint to other devs. To avoid the exception, I increase the limit and wrap the RavenDB’s session (with using the façade pattern), which among many other things notifies the admin/devs on a high number of requests per session via AppInsight (logs a warning on 15 requests and an error on 30).
RavenDB is an opinionated DB and a few things they initially got wrong, but later they changed their attitude. Not on all topics, but it’s getting there.
Conclusion
Perhaps, my story ended up being slightly longer and darker than it should.
Overall, I can say RavenDB is a very good NoSQL database for .NET developers, but the ”good” is coming with a bunch of caveats. I’m confident in my ability to develop any enterprise application with RavenDB applying the Domain-driven design (DDD) philosophy and practices.
Though, the learning curve is steep. So devs, keep the gotchas in mind and use RavenDB responsibly.
Update (November, 2019)
This post received a response from Oren Eini in his blog - re: RavenDB. Two years of pain and joy. Check it out along with a discussion below that post.
Update (September, 2021)
I have a side-project to show how various aspects of building bespoke enterprise apps can be solved with RavenDB. With source code on GitHub and available live at yabt.ravendb.net. All accompanied with a series of articles (here under tag #yabt).
Any thoughts? Comment below, on Twitter or join the Reddit discussion.
